丂18嵨枹枮偺曽偼擖応傪偛墦椂壓偝偄丅
擡幰傾僋僙僗夝愅偺巊偄曽
丂巹偼傾僋僙僗夝愅偱師偺傕偺傪巊偭偰偄傞丅
丂柍椏偺傾僋僙僗夝愅偩偗傪巊偆偑丄偙傟偼婎杮揑偵 WEB價乕僐儞宆乮夝愅梡僞僌偺杽傔崬傒曽幃乯偩丅
|
柤徧 |
僞僀僾 |
僐儊儞僩 |
| 尰嵼巊偭偰偄傞傕偺 |
Webalizer
僒乕僶乕戄梌幰偑
柍椏偱梡堄 |
僒乕僶乕儘僌
庢摼宆 |
丂枅擔偺僶僢僠張棟丅廤栺忣曬偵桪傟丄廍偄塳傟側偳側偄丅
丂儕傾儖僞僀儉偺偙偲偼壗傕傢偐傜側偄丅
丂摉擔傑偱偺椵愊偺忣曬偼偁傞偑丄摉擔偩偗偺忣曬偑朢偟偄丅
丂SSL壔屻偼専嶕娭學偵偮偄偰壗傕傢偐傜側偄丅 |
| Google Search Console |
WEB價乕僐儞宆 |
丂SSL壔屻傕Google専嶕娭學偵偮偄偰妋偐側忣曬傪摼傜傟傞丅
丂俀擔慜偖傜偄傑偱偺廤栺僨乕僞偱偁傞丅
丂僌僌偭偰傾僋僙僗偝傟偨屻偺偙偲偼傢偐傜側偄丅 |
| 埲慜偵巊偭偨傕偺 |
COLOSSAL
E-Kaiseki
ace-analyzer
丂2018擭傑偱巊梡 |
WEB價乕僐儞宆 |
丂偙偺俁偮偼僄乕僗僥僋僲儘僕乕幮偑採嫙偟偰偄傞丅
丂巹偑僒僀僩奐愝埲崀堦斣挿偔巊偭偨偺偑COLOSSAL偩丅
乽尰嵼偺僆儞儔僀儞儐乕僓乕悢乿偑尒傟偰丄儕傾儖僞僀儉側忣曬傪摼傜傟傞丅
丂偲偵偐偔棙梡壙抣偑桪傟偰偄偨偑丄採嫙傪廔椆偟偨丅 |
丂仾偺師偵棙梡
Google傾僫儕僥傿僋僗 |
WEB價乕僐儞宆 |
丂僶僢僠張棟偝傟偨忣曬偼棫攈偩偗傟偳丄屄乆偺僨乕僞偑壗傕攃埇偱偒側偄偐傜偡偖偵僀儎偵側偭偨丅
丂Google Search Console傪巊偊偽丄偙傟偼梫傜側偄偩傠偆丅
丂僒乕僶乕儘僌庢摼宆傪暪梡偟偰偄側偄側傜丄偙傟偼栶偵棫偮丅 |
丂仾偺師偵棙梡
傾僋僙僗夝愅尋媶強 |
WEB價乕僐儞宆 |
丂儘僑儅乕僋偺僶僫乕傪昞帵偡傞昁梫偑側偄偐傜巊偭偨丅
丂儕傾儖僞僀儉惈偑偁偭偰傕丄堦恖堦恖偺傾僋僙僗幰偺僒僀僩撪偱偺堏摦偑攃埇偟偯傜偄偟丄傾僂僩僾僢僩偵暼偑嫮偔丄崱傂偲偮枺椡偑側偐偭偨丅 |
丂巹偼挿擭墈棗幰偑偳偺傛偆偵乮屄恖偲偟偰偱側偔丄孮廜偲偟偰乯変偑僒僀僩傪減渏偟偨偐傪僩儗乕僗偱偒傞傾僋僙僗夝愅傪巊偭偨丅専嶕偱棃偰丄摉奩儁乕僕傪堦弖挱傔偰嫀傞庘偟偄傾僋僙僗傪懡審悢挱傔偰丄愨朷偵怹傞偨傔偩丅
丂偟偐偟丄偦偺傛偆側傾僋僙僗夝愅僒僀僩傪塣塩偡傞帠嬈偼儁僀偟側偔偰丄傕偆傎傏徚柵偟偨丅僄乕僗僥僋僲儘僕乕幮偺傾僋僙僗夝愅偺帵偟曽偼偲偵偐偔妝偟傔偨偩偗偵巆擮偱側傜側偄丅
丂壗偲偐擔乆偺忬嫷偑傛偔傢偐傞傾僋僙僗夝愅偑側偄偐偲巚偭偰偄傠傫側傕偺傪擖傟偰偼傒偨偗傟偳丄娫広偵崌傢側偔偰偡傋偰徚偟偨丅
丂娫広偵崌傢側偄劅劅偺娍帤偑偡傫側傝弌側偐偭偨丅偟傚偆偑側偄偐傜傂傜偑側偱傑偠傖偔偵偁傢側偄偲専嶕棑偵擖傟偨傜丄傑偟傖偔偵偁傢側偄偲偟側偄偲曄姺偱偒側偄偲傢偐偭偨丅
丂50擭埲忋巚偄堘偄傪偟偰偄偨丅
丂寢嬊丄巹偼忋昞偺亀尰嵼巊偭偰偄傞傕偺亁偩偗偱変枬偟偨丅偟偐偟丄偙偺傾僋僙僗夝愅偼僶僢僠張棟偱丄摉擔偺崌寁忣曬丄寧娫廤寁抣偩偗偑摼傜傟傞忣曬偩丅
丂惗儘僌偑尒傜傟傞傾僋僙僗夝愅偱嵟屻偵巊偭偨偺偼傾僋僙僗夝愅尋媶強偩偑丄偙傟偼儗億乕僩傪堏摦抂枛偺嫹偄夋柺偱尒傞偙偲傪堄幆偟偨嶌傝偱丄偟偐傕丄巹偺婓朷偵揔崌偟偨撪梕偱偼側偐偭偨丅
丂堦擭傎偳慜偵棙梡傪掆巭偟偰丄懠偵壗偲偐栶偵棫偮傕偺偑側偄偐偲専摙偟偨丅椺偊偽丄偁傞擔壗偐偺儁乕僕偵傾僋僙僗偑媫憹偟偨傜丄偄偐側傞尰徾偑婲偒偨偺偐挷傋偨偄丅儘僌偺曐懚婜娫偼抁偔偰傕傛偄偐傜丄惗儘僌傕傢偐傝傗偡偔弌偡傾僋僙僗夝愅僒僀僩傪偢乕偭偲媮傔偰偄偨丅
丂擡幰傾僋僙僗夝愅偱僌僌傞偲劅劅惗儘僌傪弌偡偐傜晄桖夣偩劅劅偲偄偆乮儐乕僓乕偺婥帩偪傪澪庌偟偨僒僀僩惂嶌幰偺乯堄尒偑偁偭偨丅婥帩偪偼傢偐傞偑丄僱僢僩偱偁傞尷傝僒乕僶乕懁偵昁梫側忣曬傪搉偡巇慻傒偱偁傞偐傜偵偼巇曽偑側偄丅夝愅棙梡幰偑惗儘僌偺屄恖揑晹暘傪巊傢側偗傟偽椙偄偩偗偺偙偲偩丅
丂偦傟偵丄傾僋僙僗幰偼儘僌傪撉傑傟偨偭偰丄尰幚偵偼夝愅棙梡幰偵偼壗傕傢偐傜側偄丅帺屓偺IP傾僪儗僗偱傕偭偰丄僒乕僶乕懁偵埆岻傒傪偟偰摦偄偰側偄尷傝怱攝偡傞昁梫偼側偄丅
擮偺堊丗僒乕僶乕塣塩幰亗夝愅棙梡幰乮僒僀僩惂嶌幰乯
丂婋尟偑偁傝摼傞働乕僗偼師偺傛偆側帪偩丅
丂僒僀僩傪弌偟偰偄傞俙抝偑俛彈偺慜偱丄俛彈偺揹巕婡婍偵傛傝摉奩僒僀僩傪奐偗偨丅
丂俙抝偼僒僀僩偵傾僋僙僗偟偨帪崗偑傢偐傞偐傜丄帪崗傪僉僀偵惗儘僌傪摿掕偱偒傞丅
丂偡傞偲丄偦偺屻俛彈偑嫽枴傪帩偭偰嵞搙偺傾僋僙僗傪偟偨偐偳偆偐挷傋傞偙偲偑偱偒傞丅偦傟偳偙傠偐丄俙抝偑IT偺弉楙幰側傜偦偺揹巕婡婍偵壗偐傪杽傔崬傫偱忣曬傪庢傝弌偡偙偲偑偱偒傞偐傕偟傟側偄丅
丂偲偄偆偙偲偱丄抦傝崌偄偐傜
偦偺恖偺僒僀僩傪徯夘偝傟偰傕丄埆堄偺壜擻惈偑枩堦偁傝摼傞応崌偼丄帺暘偺傾僋僙僗偑摿掕偝傟側偄傛偆偵峫椂偟偨傎偆偑傛偄丅
丂懳墳偼 (1) 朘栤幰偑嬌傔偰彮側偄偲巚偟偒僒僀僩偵擖傜側偄 (2) 傾僋僙僗帪崗偑摿掕偝傟側偄偙偲 (3) 巊偆IP摍巊梡娐嫬偑摿掕偝傟側偄偙偲 (4) 専嶕偟偰擖傞丅
丂
挷嵏庤抜乮仼怱攝偣偢偵僋儕僢僋乯偱師偺傛偆偵夞摎偑弌傞丅
丂偁側偨偺儕儌乕僩儂僗僩偼 xx-xx-xx-xx.bb.starcat.ne.jp偱偡丅
丂IP傾僪儗僗偼 1xx.1xx.cc.aaa 偱偡丅
丂傾僋僙僗夝愅偱偼偙偺儂僗僩柤偑帵偝傟傞丅偙傟偼僱僢僩偺巇慻傒偲偟偰偳偆偟傛偆傕側偄丅
仸 帺屓偺儕儌乕僩儂僗僩偑壗偱偁傞偐偼丄挷傋偰儊儌偟偰偍偄偨傎偆偑椙偄偱偡丅
丂傾僋僙僗夝愅傪巊偆懁偲偟偰偼丄婎杮揑偵儕儌乕僩儂僗僩傗埵抲忣曬偺傛偆側傕偺偼嫽枴偑側偄丅抦傝偨偄偺偼傾僋僙僗偵娭偡傞悢抣偺憤崌揑忣曬偩丅儂僗僩柤偐傜壗偐傪抦傝偨偔側傞帪偑偁傞偲偡傟偽丄峳傜偟偩偑丄椙惈婰偼憡屳偺傗傝偲傝偑儊乕儖偟偐側偄偐傜丄峳傜偟偺敪惗偺偟傛偆偑側偄丅
丂擡幰傾僋僙僗夝愅偼傕偆壗擭傕婥偵偐偗偰偄偨丅壛擖偟偰摦偄偨偙偲偼壗搙傕偁傞丅偱傕丄夋柺偑師偺僗僥僢僾偵恑傑側偄偺偩丅巚偄弌偟偨傛偆偵僠儍儗儞僕偟偨偗傟偳枅搙懯栚偩偭偨丅
丂偙偆偄偆僩儔僽儖偼丄Windows10 傗僂傿儖僗懳嶔僜僼僩傗僽儔僂僓側偳尨場偵偄傠傫側壜擻惈偑峫偊傜傟偰丄巹偺傛偆側愺偄抦幆偱偼杮摉偵墲惗偡傞丅
丂尰徾偼丄棙梡拞偺僣乕儖堦棗偺儁乕僕偐傜亀娗棟夋柺亁偵擖傟側偄丅柍抧偺崟偄夋柺偑弌傞偩偗偩偭偨丅
丂栤偄崌傢偣僼僅乕儉偑偁傞偑丄巹偺俹俠偺娐嫬偺栤戣偱偁傟偽丄暦偄偰傕巇曽偑側偄丅掹傔偨丅
丂2021/03/04偵劅劅Google Chrome 偵偍偄偰AdBlock偑幾杺偟偰偄傞偺偱偼側偄偐劅劅偲撍慠慚偒丄AdBlock傪掆巭偟偨傜 棙梡拞偺僣乕儖堦棗偐傜亀娗棟夋柺亁偵堏傞偙偲偑偱偒偨丅
丂憗懍夝愅梡僞僌傪擖庤偟偰昁梫側嶌嬈傪偟偨丅
丂偟偐偟丄屗榝偆偙偲偑懡偐偭偨丅
丂擡幰傾僋僙僗夝愅偵偮偄偰専嶕偟偰傕丄摉偨傝慜偺忣曬偟偐弌偰偙側偄丅搊榐庤懕傗僞僌偺擖庤曽朄傗僞僌偺愝抲曽朄偺傛偆側傕偺偱丄偦傟偼擡幰傾僋僙僗夝愅偺僒僀僩偺巜帵丒愢柧傪尒傟偽傢偐傞偙偲偩丅傕偭偲幚梡揑側愢柧丄傗傞帪偵屗榝偄傗偡偄偙偲偺愢柧偑弌偰偙側偄丅
丂偙偆傗傝側偝偄偲偄偆嬶懱揑側傕偺乛椺帵偑側偄偲丄弶傔偰偺乮僱僢僩偵娭傢傞乯摦嶌偼傗傝偵偔偄丅
丂偦偙偱丄堦偮愢柧彂傪彂偔偙偲偵偟偨丅傾僋僙僗夝愅傪弶傔偰棙梡偡傞恖偼丄懠偵傕抦傜側偄偙偲偑偁傞偐傕偟傟側偄丅
丂俹俠偱摫擖偡傞僒僀僩偱丄廂榐儁乕僕悢偑懡偄僒僀僩乮50儁乕僕埲忋乯傪擮摢偵愢柧偟傑偡丅
侾丏儘僌僀儞傑偱
丂擡幰傾僋僙僗夝愅偺僒僀僩偵偼丄怴婯儐乕僓乕搊榐傛傝傕丄Google側偳偺僒乕價僗傾僇僂儞僩傪梡偄偨傎偆偑娙扨偱偡丅
丂僒僀僩惂嶌幰偵Google偺僒乕價僗傾僇僂儞僩偼昁恵偱偡丅
丂SSL壔偵傛偭偰専嶕娭學偺忣曬偼 Google Search Console 偵棅傜偞傞傪摼傑偣傫丅偡傞偲 G儊乕儖傪擖庤偡傞昁梫偑惗偠傑偡丅Google偺傾僇僂儞僩偼昁恵偱偡丅
俀丏娗棟儁乕僕偵偮偔偲乽怴偟偄僒乕價僗傪捛壛偡傞乿偺張棟傪偡傞丅
丂捛壛偱偒偨僒乕價僗柤徧偵儕儞僋張棟偑擖偭偰偄傞偺偱丄偙傟傪僋儕僢僋偡傞丅
丂(拲)
丂巹偺応崌丄柍抧偺崟偄夋柺偑弌偰丄壗偲傕側傜側偐偭偨仺俁擭傎偳乮巚偄弌偟偰偼挧愴偟偰乯擸傫偩丅
丂挿偄埆愴嬯摤偩偭偨偑丄AdBlock傪巭傔偰儕儘乕僪偟偨傜摨僒僀僩偺愢柧夋柺偱尒偨亀娗棟儁乕僕亁偑傛偆傗偔尰傟偨丅
俁丏娗棟儁乕僕偺嵍抂偺壓晹丄婎杮愝掕偲夝愅儁乕僕愝掕偺偲偙傠傪傛偔挱傔偰丄偦偺偲偍傝傗傞丅
丂偦偺捠傝傗傞帺怣偑側偄応崌偼擡幰傾僋僙僗夝愅偱僌僌偭偰偄傠偄傠挱傔傞丅
丂偨偩丄婎杮愝掕偲夝愅儁乕僕愝掕偺偲偙傠傪傛偔挱傔傟偽扤偱傕憐憸偱偒傞偙偲偑彂偄偰偁傞偩偗丅
丂偙偙偐傜偼巹偑傗偭偨傗傝曽偱丄嶲峫傑偱偵宖偘傞傕偺偩丅偙偺捠傝偣偹偽側傜側偄偙偲偼側偄丅
丂廂傔偨僼傽僀儖悢偑懡偄僒僀僩偵嶲峫偵側傞傗傝曽偩偲巚偆丅
係丏僼傽僀儖専嶕 Davas 傪梡堄偡傞丅乮偙傟偲摨偠埲忋偺専嶕抲姺僜僼僩偑偁傟偽偦傟偱偳偆偧乯
丂僜僼僩 Davas偱僌僌偭偰丄師偺愢柧彂偒偺柍椏僜僼僩傪擖庤偡傞丅
丒僼僅儖僟撪偺僼傽僀儖傪堦妵偟偰専嶕丄抲姺偱偒傑偡丅
丒敪尒偟偨僥僉僗僩偺慜屻傪堦棗昞帵偟丄昁梫側傕偺偩偗抲姺偱偒傑偡丅
丒敪尒埵抲傪僄僨傿僞偱昞帵偟偰妋擣偱偒傑偡丅
丒儚乕僪専嶕偑壜擻偱偡丅
丒専嶕丄抲姺偱惓婯昞尰偑巊偊傑偡丅
(1) 昁梫側曄姺傪偡傞丅乮偨偔偝傫偺html僼傽僀儖偵堦妵偺曄姺張棟傪偡傞乯
(2) 媮傔傜傟偰偄傞偺偼 <BODY> 偺壓偵夝愅梡僞僌傪憓擖偡傞偙偲丅
丂僞僌偼
<!--shinobi1--><script type="text/javascript" src="//xa.shinobi.jp/ufo/696944400"></script>
(棯)/gg?696944400" target="_blank">
(棯)/ll?696944400" border=
(棯)><!--shinobi2-->
丂偺傛偆側姶偠偱丄偐側傝挿偄乮384暥帤乯丅
丂Davas 傪婲摦偟丄尰傟偨
Davas - 忦審擖椡偺専嶕暥帤楍偺棑偵
<BODY> 偲擖傟傞丅
丂
懳徾僼傽僀儖偺忦審偵
*.txt *.htm *.html 傪慖傇丅
丂懳徾僼僅儖僟偵html僼傽僀儖偺奿擺応強傪巜掕偡傞
乮僒僽僼僅儖僟傕専嶕偵娷傑傟傞傛偆偵巜掕偡傞乯丅
丂偡傞偲丄
Davas - 専嶕寢壥偵栚揑偺傕偺偑偢傜傝偲帵偝傟傞丅
丂摨昞偺壓棑亀抲姺暥帤楍亁偺強偵偁傞 <BODY> 偵懕偗偰師傪彂偒懌偡丅
\n<!--shinobi1--><script type="text/javascript" src="//xa.shinobi.jp/ufo/696944400"></script>
(棯)/gg?696944400" target="_blank">
(棯)/ll?696944400" border=
(棯)><!--shinobi2-->
丂
\n偼夵峴僐乕僪偱偁傞丅Davas 偼html僞僌傗
\n側偳傪張棟偺偱偒傞偺偱偁傝偑偨偄丅
仜夵峴傪擖傟偨傎偆偑屻偺嶌嬈偑偟傗偡偄偩傠偆丅
仜椙惈婰偼400傪挻偊傞僼傽僀儖悢偩偑丄偙偺挿暥偺憓擖偑弖帪偵偱偒偨丅
| <BODY ID="sex"> |
<BODY ID="soap"> |
<BODY ID="hooker"> |
<BODY ID="higi"> |
| 忋庤側僙僢僋僗傪峫偊傞 |
僜乕僾梀傃傪峫偊傞 |
僜乕僾忟傪垽偟傓 |
僜乕僾忟偺旈媄傪峫偊傞 |
| <BODY ID="play"> |
<BODY ID="shokai"> |
<BODY ID="talk"> |
<BODY ID="essay"> |
| 嬥捗墍梀傃偺庤堷偒 |
弶夛偺嬥捗墍梀傃 |
嬥捗墍梀傃偺幚榐 |
偊傠偊傠峫嶡 |
丂丂丂偩偐傜丄曄姺乮彂偒懌偟乯偑偙偺8審偱昁梫偵側傞丅
丂(3) html僼傽僀儖偵夝愅梡僞僌傪擖傟偨屻昁梫側廋惓傪偡傞丅
(愢柧) 巹偑偙傟傑偱巊偭偨傾僋僙僗夝愅偼慡偰扨堦偺僞僌偩偭偨偑丄擡幰傾僋僙僗夝愅偼暋悢偩丅
(a) 夝愅偟偨偄儁乕僕偑10審偁傟偽丄偙偺10儢偺僞僌傪暘偗傞昁梫偑偁傞丅(100審傑偱壜擻)
丂椺偊偽丄廂榐儁乕僕偑慡晹偱150偁傟偽丄100審傪師偺傛偆偵暘偗傞丅
嬻偒仼梊旛 2審丄偦偺1嶌偱僨乕僞傪庢傞傕偺 90審丄傑偲傔偰僨乕僞傪庢傞傕偺 8審
150亅90亖60丂丂偙偺60僼傽僀儖傪8儢偺廤栺儁乕僕偵廤傔傞丅
(b) 婎杮愝掕偺儁乕僕偺拞傎偳偵亀Page侾亁偺棑偑偁傞丅(埲壓丄偙傟傪儁乕僕斣崋偲偄偆)
丂偙偙偐傜Page俀傪慖戰偡傞偲丄Page侾偲偼嬐偐偵堘偆HTML僞僌偑帵偝傟傞丅
<!--shinobi1--><script type="text/javascript" src="//xa.shinobi.jp/ufo/696944400"></script>(棯)/gg?696944400" target="_blank">(棯)/ll?696944400" border=(棯)><!--shinobi2-->
丂偺愒帤偺悢帤偑師偺傛偆偵曄壔偡傞丅
| Page 1乣10 |
Page 11乣36 |
Page 37乣62 |
Page 63乣72 |
Page 73乣98 |
Page 99乣 |
| 楢斣 00乣09 |
楢斣 0a乣0z |
楢斣 0A乣0Z |
楢斣 10乣19 |
楢斣 1a乣1z |
楢斣 1A乣 |
丂師偺傛偆偵儁乕僕斣崋丄乮儐乕僓乕屌桳斣崋偵晅壛偝傟偨乯楢斣丄儁乕僕柤傪昞偵揨傔傞丅
丂儁乕僕斣崋偲偼儁乕僕柤傪廂傔傞偨傔亀擡幰亁偑梡堄偟偨壖偺傕偺偱偁傞丅
Page
斣崋 |
僞僌偺
拞偺
楢斣 |
儁乕僕柤 |
Page
斣崋 |
僞僌偺
拞偺
楢斣 |
儁乕僕柤 |
| 侾 |
00 |
index.html |
42 |
0F |
misunderstanding.ht |
| 俀 |
01 |
sexgate.html |
43 |
0G |
number_one.html |
| 俁 |
02 |
偦偺懠 sex-xx.html |
44 |
0H |
higigate.html |
| 係 |
03 |
cunnilingus.html |
45 |
0I |
偦偺懠 higi-xx.html |
| 俆 |
04 |
levitra.html |
46 |
0J |
isu_arai.html |
| 俇 |
05 |
analsex.html |
47 |
0K |
bases_soap_lady.ht |
| 俈 |
06 |
creampie.html |
48 |
0L |
soku_anal_name.html |
| 俉 |
07 |
sex_taii.html |
49 |
0M |
lingerie.html |
| 俋 |
08 |
sex_manual1.html |
50 |
0N |
fellatio.html |
| 10 |
09 |
sex_manual2.html |
51 |
0O |
waza_iroiro.html |
| 11 |
0a |
sex_manual3.html |
52 |
0P |
kanazu_pa.html |
| 12 |
0Z |
sex_manual4.html |
53 |
0Q |
偦偺懠 kanazu.html |
| 13 |
0c |
jyoseiki.html |
54 |
0R |
ns_soap.html |
| 14 |
0d |
kyokon.html |
55 |
0S |
kanazu_2.html |
| 15 |
0e |
multiorgasm.html |
56 |
0T |
ns_koukyu.html |
| 16 |
0f |
soapgate.html |
57 |
0U |
en_group.html |
| 17 |
0g |
偦偺懠 soap-xx.html |
58 |
0V |
kanazu_list.html |
| 18 |
0h |
nakadashi.html |
59 |
0W |
my_playstyle.html |
| 19 |
0i |
deep_kiss.html |
60 |
0X |
ns_kanazu.html |
| 20 |
0j |
soap_nirinsya.html |
61 |
0Y |
kanazuen-try.html |
| 21 |
0k |
soap_beginner.html |
62 |
0Z |
rubul.html |
| 22 |
0l |
majimesoap.html |
63 |
10 |
the_end.html |
| 23 |
0m |
tengai_date.html |
64 |
11 |
rgroup2.html |
| 24 |
0n |
soap_photography.ht |
65 |
12 |
rgroup.html |
| 25 |
0o |
abnormal_play.html |
67 |
14 |
shokaigate.html |
| 26 |
0p |
soap_analsex.html |
68 |
15 |
偦偺懠shokaixx.html |
| 27 |
0q |
thinking.html |
69 |
16 |
talkgate.html |
| 28 |
0r |
manual_01.html |
70 |
17 |
偦偺懠 talkxx.html |
| 29 |
0s |
judgment.html |
71 |
18 |
anal_ecstasy.html |
| 37 |
0A |
ecstasy.html |
83 |
1k |
essaygate.html |
| 38 |
0B |
henna_kyaku.html |
84 |
1l |
偦偺懠 essayxx.html |
| 39 |
0C |
ikina_kyaku.html |
85 |
1m |
aging.html |
| 40 |
0D |
hooker.html |
88 |
1p |
tousui.html |
| 41 |
0E |
偦偺懠 jyojyo.html |
89 |
1q |
偦偺懠 moviexx.html |
Page斣崋偵懳偡傞儁乕僕柤偼尒杮偲偟偰揔摉偵抲偄偨傕偺偱偁傞丅
(c) 100儁乕僕梡堄偝傟偰偄傞偑丄忋昞偼彮偟婰嵹傪徣偄偰偁傞丅
丂億僀儞僩偼丄屄暿偺廤寁傪晄梫偲偡傞儁乕僕傪亀偦偺懠亁偱傑偲傔偨偙偲丅
丂椺偊偽丄偦偺懠 sex-xx.html偼偙傫側html偼懚嵼偟側偔偰丄
忋庤偵僙僢僋僗傪峫偊傞偺拞偱丄儁乕僕斣崋04乣15偵偰攃埇偡傞僼傽僀儖埲奜偺傕偺偵偮偄偰僨乕僞傪揨傔傞奿擺屔偩丅
丂偙偺傗傝曽偱慡偰偑攃埇偝傟傞丅傾僋僙僗偺彮側偄儁乕僕偼偦偺懠戝惃偱傛偄偲偡傞丅
丂乮嶲峫乯
椙惈婰偺僼傽僀儖
(d) 楢斣偺彂姺偼僼僅儖僟乕巜掕偱堦妵偱峴偆丅
丂椺偊偽丄嬥捗墍偺庤堷偒偺僼僅儖僟乕偺慡僼傽僀儖傪懳徾偵偟偰乮偙傟偼婛偵僨僼僅儖僩偺楢斣00偱夝愅梡僞僌偑杽傔崬傑傟偰偄傞乯丄忋偺昞偺偦偺懠 kanazu.html偺楢斣 0Q 偵抲偒姺偊傞丅
丂抲偒姺偊偨屻丄0Q偵偟偰偼側傜側偄傕偺傪堦偮堦偮惓偟偄楢斣偵捈偡丅
俆丏楢斣偺廋惓傪廔偊偨傜僼傽僀儖傪傾僢僾儘乕僪偡傞丅
丂峏偵丄娗棟夋柺偱丄夝愅儁乕僕愝掕偵恑傒丄儁乕僕柤傪侾偐傜弴偵慡偰偁傜偨傔傞丅
丂椺偊偽丄昞偺cunnilingus.html偺儁乕僕柤乮斣崋乯傪亀cunnilingus.html亁偵捈偝側偄偲壗偺偙偲偐傢偐傜側偄丅亀僋儞僯儕儞僌僗偺巇曽亁偲偟偰傕傛偄偑丄僼傽僀儖柤偺傎偆偑巊偄傗偡偄偐傕丅
俇丏庤尦偺僼傽僀儖偼僽儔僂僓偱棫偪忋偘傞偲夝愅僞僌偺塭嬁偱摦偒偑埆偔側傞偙偲偑偁傞丅
丂偦偺帪偼師偺傛偆偵偡傞丅
丂<!--shinobi1--><script type="text/javascript" src= 傪 Davas偵擖傟偰専嶕偡傞丅
丂src= 偺偲偙傠傪 Davas傪巊偭偰 src!= 偲偡傞乮慡僼傽僀儖堦妵張棟乯丅偙傟偱偙偺僼傽僀儖偼儘乕僇儖娐嫬偵偰擡幰傾僋僙僗夝愅偲柍娭學偵側傞丅
丂偙偺僼傽僀儖傪偦偺屻庤捈偟偟偰嵞搙倳倫偡傞帪偼 src= 偵栠偝偹偽側傜側偄丅
丂椙惈婰偺偳偙偐偺儁乕僕傪僟僂儞儘乕僪偟偰曐懚偡傞恖偐偄傞偐傕偟傟側偄丅
丂偦偺応崌傕摉奩html僼傽僀儖傪儊儌挔偱奐偄偰
丂<!--shinobi1-->script type="text/javascript" src= 偺 src= 傪 src!= 偲偡傞丅
丂<!--shinobi1--> 乣 <!--shinobi2--> 偺慡暥傪徚偟偰傕椙偄丅
丂偙偆偟側偄偲擡幰傾僋僙僗夝愅偺僒僀僩偵晄梫側傾僋僙僗傪偟偰摦偒偑抶偔側傞丅
丂側偍丄巹偺俹俠偺拞偺html僼傽僀儖傪僽儔僂僓偱尒偨帪丄傾僋僙僗夝愅偱偳偆側傞偺偐偼師偺捠傝丅
丂埲慜偺COLOSSAL側偳劅劅帺屓偺僼傽僀儖偺撉傒崬傒偑傾僋僙僗夝愅偱懆偊傜傟偨丅
丂擡幰傾僋僙僗夝愅劅劅劅帺屓偺僼傽僀儖偺撉傒崬傒偑傾僋僙僗夝愅偱懆偊傜傟偰偄側偄丅
丂偩偐傜丄COLOSSAL傪巊偭偨帪偵偼丄扤偐偑椙惈婰傪俢俴偟偰挱傔傞偲丄巹偼偦偺儘僌傪尒偰劅劅偁傟偭丄僟僂儞儘乕僪偟偰挱傔偰偄傞偺偐側丠劅劅偲婥偑偮偔偙偲偑偁偭偨丅
丂html僼傽僀儖傪俢俴偡傞帪偼丄拞偵偁傞傾僋僙僗夝愅傪柍岠偵偟傑偟傚偆丅
丂WEB價乕僐儞宆偺傾僋僙僗夝愅偱偼 栚揑偺僂僃僽僒僀僩偩偗傪夝愅偺懳徾偲偡傞偙偲偑朷傑傟傞丅
丂1.摦嶌偼懍偄丅
丂擡幰傾僋僙僗夝愅偼僞僌偺僨乕僞偟偐庢偭偰偄側偄偐傜憗偄偺偩傠偆丅
丂夝愅梡僞僌偑侾庬偺傒偩偲丄僞僌偑杽傔崬傑傟偨僼傽僀儖偐傜昁梫側傕偺乮椺偊偽僼傽僀儖柤乯傪撉傒崬傓昁梫偑偁傞丅
丂2.昞偼尒傗偡偄丅
丂Google傾僫儕僥傿僋僗偺傛偆偵尒塰偊偱彑晧偲偄偆嬅偭偨嶌昞傪偟偰偄側偄偺偑傛傠偟偄丅
丂傾僋僙僗夝愅尋媶強偺傛偆偵撈傝傛偑傝偺垻曫側梡岅傪巊偭偰偄側偄偺偑椙偄丅
丂擡幰傾僋僙僗夝愅偼乮100審敍傝偺寢壥乯僒僀僩偺峔惉儁乕僕偺拞偱廳梫惈偺掅偄傕偺傪亀偦偺懠亁偱揨傔偞傞傪摼側偄偺偑寢峔偩丅
丂3.儕傾儖僞僀儉偺忬懺偑傢偐偭偰偲偰傕偁傝偑偨偄丅
丂傾僋僙僗夝愅尋媶強偺傛偆偵惗儘僌傪弌偟偰傕忣曬検偑朢偟偔偰丄侾偮偺傾僋僙僗偺帰屻偺墈棗偺恑傒曽偑傢偐傝偵偔偄偺偼柺敀偔側偄丅偦偺揰丄擡幰傾僋僙僗夝愅偼寢峔偩傠偆丅
丂師偼偁傞擔偺憗挬偺摉擔僨乕僞偩丅乮塃偼愗傟偰偄傞乯
丂嵟弶偵傾僋僙僗偝傟偨儁乕僕偺暘晍偑攃埇偱偒傞偺偑婐偟偄丅
丂変偑僒僀僩偼僩僢僾儁乕僕偐傜擖傞偺偑懚奜彮側偄丅専嶕棅傝偩丅
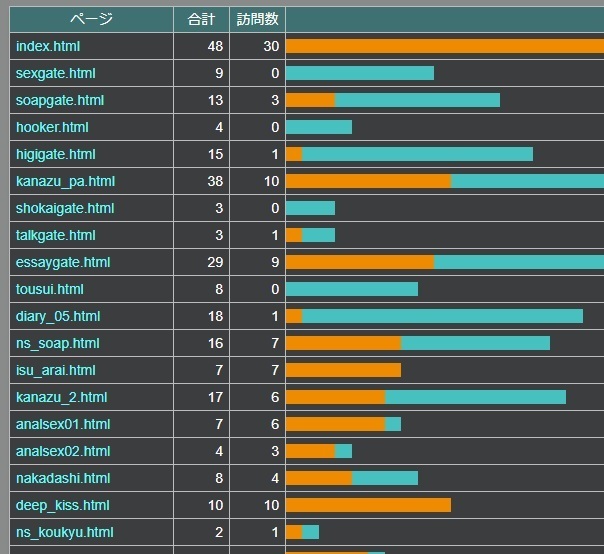
| 儁乕僕 |
僞僀僩儖 |
崌寁 |
朘栤悢 |
傾僋僙僗悢 |
| index.html |
僩僢僾儁乕僕 |
48 |
30 |
18 |
| sexgate.html |
忋庤側僙僢僋僗傪峫偊傞 |
9 |
0 |
9 |
| soapgate.html |
僜乕僾梀傃傪峫偊傞 |
13 |
3 |
10 |
| essaygate.html |
偊傠偊傠峫嶡 |
29 |
9 |
20 |
| isu_arai.html |
僺儞僋僠僃傾側偳偺堉巕偺僾儗僀 |
7 |
7 |
0 |
丂惵怓偺朹僌儔僼偼傾僋僙僗悢傪帵偡丅
丂忋庤側僙僢僋僗傪峫偊傞偺儁乕僕偼僒僀僩撪偺偳偙偐偐傜傾僋僙僗偟偨偺偑9審偱丄捈愙偙偙偵傾僋僙僗偟偨偺偑0審丄僺儞僋僠僃傾側偳偺堉巕偺僾儗僀偼僒僀僩撪偺偳偙偐偐傜傾僋僙僗偟偨偺偑0審偱丄乮専嶕偵傛偭偰乯捈愙偙偙偵傾僋僙僗偟偨偺偑7審偲傢偐傞丅
4.僨乕僞曐懚婜娫偑抁偄偑丄巹偼尰忬攃埇偺偨傔偵巊偆偐傜丄偙偺偙偲偼栤戣側偟丅
丂崱壗偑婲偒偰偄傞偐抦傞偙偲偑偱偒傞偙偲偼廳梫偩丅
丂僒僀僩傊偺傾僋僙僗偺徻偟偄僨乕僞傪悢擭傇傝偵尒偰丄堏摦抂枛偺彫偝側夋柺偱尒偰偄傞恖偑偁傑傝偵傕懡偄偐傜嬃偄偨丅
丂崱巹偺僒僀僩傪尒偰偄傞恖偑偄傞偲偄偆庤墳偊偼幚偵憂嶌堄梸傪巟偊偰偔傟傞丅
丂擡幰傾僋僙僗夝愅傕梡岅偺夝愢偑側偄丅偙傟傪巊偭偰傢偐傜側偄偙偲偑偁傞丅
丂堦擔偺悇堏偑師偺傛偆偵帵偝傟傞丅
| 帪娫暿 |
儁乕僕暿 |
| 帪崗 |
崌寁 |
朘栤悢 |
儁乕僕 |
崌寁 |
朘栤悢 |
| 0:00 |
150 |
62 |
index.html |
棯 |
棯 |
| 1:00 |
168 |
40 |
talkgate.html |
棯 |
棯 |
| 2:00 |
82 |
45 |
essaygate.html |
棯 |
棯 |
| 丂拞丂棯 |
丂拞丂棯 |
| 22:00 |
257 |
97 |
isu_arai.html |
棯 |
棯 |
| 23:00 |
237 |
85 |
cunnilingus.html |
棯 |
棯 |
丂嵍偺朘栤幰悢偺崌寁抣偲塃偺朘栤幰悢偺崌寁抣偑摨偠抣偱丄偙傟偑懠偺儁乕僕偱傕偦偺擔偺朘栤幰悢偲偟偰弌偝傟傞丅
丂偙偺朘栤幰悢偑偳偺傛偆偵寛傔傜傟偰偄傞偺偐愢柧偑側偄丅
丂慜擔23:40偵偳偙偐偺儁乕僕偵傾僋僙僗偟偨恖偑丄00:05偵暿偺儁乕僕偵堏偭偨帪丄偦傟偼慜擔偩偗偱側偔摉擔偺朘栤幰偵傕側傞偺偐丄偦傟偲傕摉擔偺傎偆偼傾僋僙僗幰偵側傞偺偐丅
丂7:55偵偳偙偐偺儁乕僕偵傾僋僙僗偟偨恖偑丄8:01偵暿偺儁乕僕偵堏偭偨帪丄8:00偺棑偱偼朘栤幰偵側傞偺偐傾僋僙僗幰偵側傞偺偐丅
丂isu_arai.html偵傾僋僙僗偟偨恖偑index.html偵堏摦偟偨帪丄index.html偺棑偱偼朘栤幰偵側傞偺偐傾僋僙僗幰偵側傞偺偐丅
丂忋偺儁乕僕暿僨乕僞偺夋憸偺悢抣傪尒傞偲丄懡暘嬌椡朘栤幰偺夁忚僇僂儞僩傪梷偊偰偄傞偲巚偆丅梫偡傞偵丄帪娫暿偺昞偺帪娫懷傗儁乕僕暿偺昞偺儁乕僕偑張彈偐寠偁偒偐偺敾掕偺扨埵偵側偭偰偄側偄偩傠偆丅
丂偟偐偟丄椙惈婰偐傜堦扷嫀偭偰侾帪娫屻偵嵞搙棃偨帪丄偦傟偼怴偨側朘栤幰偵側傞偺偐偳偆偐婥偵側傞丅
丂儁乕僕暿偺昞偺朘栤幰悢偑摉奩儁乕僕偵専嶕偱擖偭偨悢偲奣偹懳墳偟偰偄傞傛偆偱丄偙偺忣曬偼巹偵偼偲偰傕嫽枴怺偄丅
丂師偵傢偐傜側偄偙偲偼丄惗儘僌偺昞偱儕儞僋尦偲偟偰宖偘傜傟偰偄傞傕偺偵偮偄偰偩丅
丂https://ryoseiki.jp/essay/essaygate.html 偲 essaygate.html 偺擇捠傝偺偁傞丅
丂https://ryoseiki.jp/ 偲 index.html 偺擇捠傝偺偁傞丅
丂偙偺庢傝埖偄偺嵎偺棟桼傪抦傝偨偄丅
丂側偍丄儕儞僋尦摑寁偵https://ryoseiki.jp/essay/essaygate.html傕https://ryoseiki.jp/傕弌偰偔傞丅僒僀僩撪堏摦偲偟偰張棟偝傟偨傕偺偲偺堘偄傪抦傝偨偄丅
丂梫偡傞偵丄傾僋僙僗夝愅偺張棟傪偳偺傛偆偵偟偰偄傞偺偐堦愗愢柧偑側偄偺偑柺敀偔側偄丅
丂擡幰傾僋僙僗夝愅傪擖傟偰椙偐偭偨偲巚偆偺偼師偩丅
丂(1) 奺儁乕僕偺侾擔偺傾僋僙僗審悢偑懄嵗偵傢偐傞丅
丂(2) 奺儁乕僕偺侾擔偺惗儘僌偑挷傋傜傟傞丅
丂偁傞儁乕僕偑媫偵傾僋僙僗傪憹傗偟偨帪丄懠強偐傜偺儕儞僋丄専嶕偺宖嵹偺岲揮偺偳偪傜偑尨場偐挷傋傜傟傞偺偼偁傝偑偨偄丅
乮愮屗廍攞丂挊乯